We will explored the idea behind Hadoop and how it is used in System Design.
Table of contents:
- Introduction to Hadoop
- Big Data and its challenges
- Hadoop as a solution
- Components of Hadoop
- Hadoop vs Relational database management system (RDBMS)
- Use case of Hadoop
Introduction to Hadoop
Hadoop is a framework of open-source software utilities that processed data in parallel while managing Big Data storage in a distributed way. Hadoop is able to efficiently break up Big Data processing across multiple commodity computer (DataNodes) and then combine the results.
Big Data and its challenges
Big Data are massive amount of data which cannot be stored, processed and analyzed using the traditional ways like a Relational Database Management System (RDBMS). Big Data include Structured data (such as database, spreadsheets), Semi-structured data (emails, html pages, etc) and Unstructured data (messages posted on social network such as Twitter, images, videos,etc). Volume, Velocity, Variety, Value, Veracity are the “5Vs” of Big Data which are also termed as the characteristics of Big Data.
In the early days, there are only limited data to store and processed. For instance, structured data such as database require only one processor unit and one storage unit. SQL was used to query database and the data were neatly stored in rows and columns like an excel spreadsheet. As the rate of data generation increased in recent years, it result in high data volume with different data format. The current single processor and single central storage unit model became the bottleneck.
Hadoop as a solution
The single processor was not enough to process such high volume of different kind of data as it was very time consuming. Due to the single storage unit acting as a bottleneck, network overhead was produced.
Hadoop enabled parallel processing with distributed storage. Large amounts of data were processed quickly by using many processors. Each processor makes use of distributed storage. Data storage and access are made simple by this. Since there was no need to wait for the data to be pulled or processed, Hadoop operated without creating network overhead or a bottleneck.
Components of Hadoop
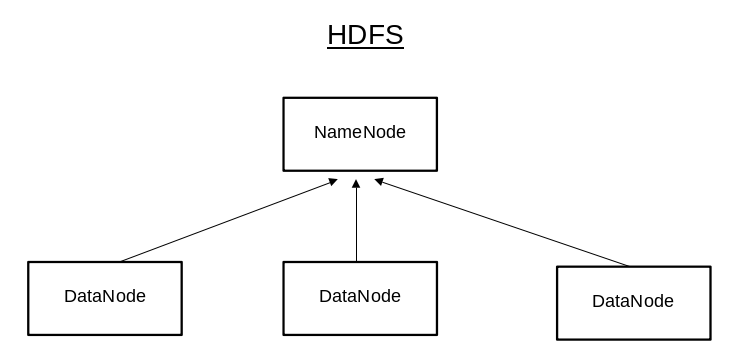
There are three components of Hadoop. The Hadoop Distributed File System (HDFS), MapReduce and Yet Another Resource Negotiator (YARN).
Hadoop Distributed File System (HDFS)
HDFS is the storage unit, it contain a Single NameNode and multiple DataNodes. The NameNode maintain and manage the DataNode and the DataNodes store the actual data, it perform the reading, writing, processing and replication of data. This replication of data among the DataNodes is how the Hadoop framework handle the DataNode failures.
Datanode sent a Heartbeat (a signal) every 3 seconds to the Namenode to indicate that it is alive. If there is an absence of heartbeat for a period of 10 minutes, a ‘Heartbeat Lost’ condition occurs and the corresponding DataNode is deemed to be dead/unavailable.
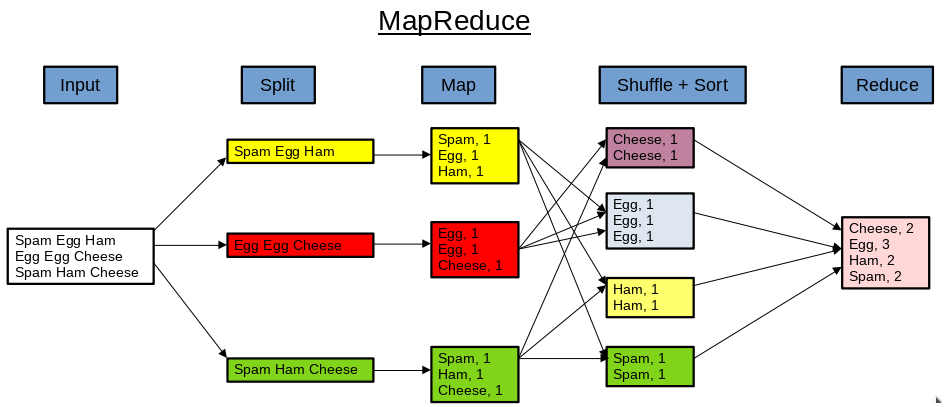
MapReduce
MapReduce is the processing unit, it is a Programming Algorithm where huge data is processed in a parallel and distributed manner. The application is divided into many small fragments of work, the processing is performed at the DataNodes and the result is sent to the NameNode.
The input data is first split into chunks of data. Next the chunks of data are processed in parallel by map task. It is then sorted and label with the occurrence number. At the reduce task, aggregation take place and the output is obtained.
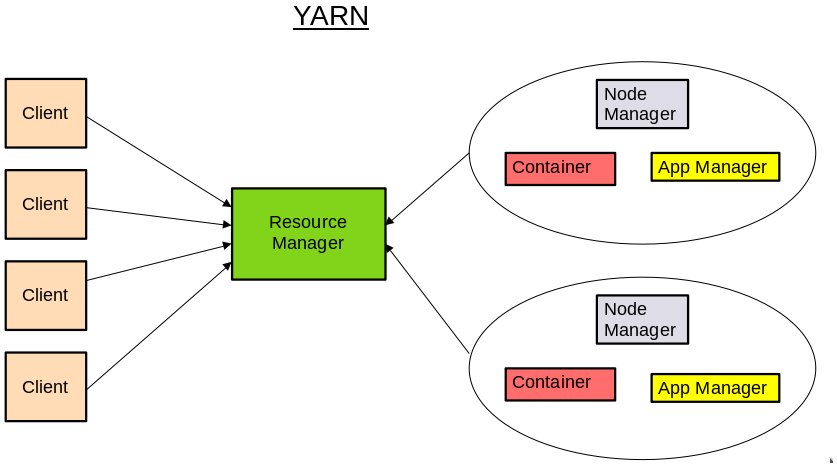
Yet Another Resource Negotiator (YARN)
YARN is the resource management unit of Hadoop. Its acts as an operating system to the Hadoop framework and performs the management of cluster resources and job scheduling. The workflow is as follow:
- When the clients submit the MapReduce jobs, it get sent to the Resource manager.
- The Resource manager is responsible for resource allocation and management. Here the Resource manager allocate a Container (a collection of physical resources such as CPU and RAM) to start the Application Manager.
- The Application Manager register with the Resource manager and request containers from the Node Manager (manages the nodes and monitor resource usage).
- Application code is executed in the Container.
- Once the processing is complete, the Application Manager deregister with the Resource Manager.
Hadoop vs RDBMS
The first difference is the schema on read approach by Hadoop and schema on write approach by RDBMS. In Hadoop, there is no restriction of what kind of data get to be stored in the HDFS. Rather than preconfiguring the structure of data, the application code will configure the data when the application read it. This is in contrast to the schema on write approach by RDBMS. Before inputting data into the database, we need to find out the database structure, modify the data sturcture so that it meet the data types the database is expecting. The database will reject the data if it does not conform to what it is expecting.
Second difference is that data in Hadoop is a compressed text file or other data types and it is replicated across multiple DataNodes in the HDFS. Whereas in RDBMS, the data is stored in a logical form with linked tables and defined columns.
Lastly, let assume that there are DataNode failure in Hadoop resulting in incomplete data set. In this instance Hadoop would not hold up the response to the user. It would provide the user an immediate answer and eventually it would have a consistent answer. The eventual consistency methodology in Hadoop is a better model for reading continuously updating feeds of unstructured data across 1000’s of servers.
On the other hand, RDBMS take a two phase commit approach. RDBMS must have complete consistency across all the nodes before it release anything to the user. The RDBMS two phase commit methodology is well suited for managing and rolling up transactions, so we know we got the right answer.
Use case of Hadoop
Lets take the “satellite view” of Google Maps as an example. How can large amount of image data files (different quality and taken at different period in time) from various content provider (input) be processed into the “satellite view” for users.
First divide the entire region into many smaller “grids” assign with fixed location IDs (latitude and longitude are useful unique IDs). Split the image data files into smaller tiles according to the “grids” they cover. Secondly, Map the smaller image with the image filename (key) and the corresponding image data (value).
Next, we Sort the image data according to their timestamp (date captured) and quality (resolution). Finally, we Reduce by overlapping and merging similar image data in the same grid they occupy. The output after using MapReduce to process the large amount of image data files will be the “satellite view” of Google Maps.
This article was originally published at OpenGenus: